![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
This chapter includes:
CVS (Concurrent Versions System) is an open-source tool used for managing versions of files. You can put any types of files under CVS control, but this chapter concentrates on source and other text files.
Version control is the ability to track changes in a file over time. Each time a file is changed, the date, the name of the user who changed the file, and a description are all recorded. This lets you track when the file changed, who changed it, and why. CVS can also help coordinate changes made to a single file by many users.
Using CVS for controlling versions of source files lets you mark which changes should be part of a software release and which shouldn't. This means you can release a project while continuing to work on future features. It is this concurrency that makes using CVS for software version control so popular.
We'll start off with the basics of using CVS, from the initial setup to manipulating your source files. We'll also cover more advanced CVS concepts, such as concurrent development and remote access.
For more information about CVS, including the full CVS User's Guide, see http://www.nongnu.org/cvs/.
CVS stores your files in a central place called a repository. The repository is stored on disk, either on your local machine or on a remote server. This section describes the locally stored version.
Every time you make changes to a file that's stored in CVS, a new revision is created. Each revision includes the date of the change, the name of the user who made the change, and a log message that describes the change. You can retrieve arbitrary revisions of a file for inspection at any time. You can use symbolic names, called tags, to mark a particular revision for easy reference.
A revision is denoted by a sequence of numbers and dots. It's analogous to the standard numbering scheme used for versions of software. For example, a file called foo.c might have had three changes over the last few days. The first revision would be numbered 1.1, the second would be 1.2, and the third 1.3. CVS automatically assigns the numbers and uses them internally. You'll have to use these numbers on many occasions.
The changes in foo.c are cumulative, so revision 1.3 contains all the changes made between 1.1 and 1.2, as well as the changes made between 1.2 and 1.3.
How does CVS know when a file has changed? Does it create a new revision every time you save a file?
You don't actually manipulate files directly in the repository. Instead you create a copy of the repository on your hard disk. You make any changes there and when you're satisfied with the changes, you tell CVS to put those changes into the repository and create a new revision. This process is called checking in. The check-in is the point at which you enter the reason for the change made.
How does your local copy of the repository get created? This is the opposite of checking in. Checking out creates a copy of the repository, complete with state information. Normally, you'll want to take a snapshot of the current state of the repository, but there are times when you want more control over which revisions of files are checked out. There are many options for this, including using symbolic names and explicit dates.
To check files in and out, you must first create a repository. For brand new projects, you create new files and add them to the repository as you go. For existing projects that aren't under version control, you can import the entire project with a single command.
All of the operations above need to know where the repository is. There is no default. The repository is simply a directory name; you can specify it via a command-line option or an environment variable.
CVS frequently asks you for information by starting an editor with a template in it. You can control which editor CVS invokes, by setting the EDITOR environment variable. For example, to use the Photon editor, ped, put this in your .profile:
export EDITOR=ped
For information about the available editors, see Using Editors; for more information about .profile, see Configuring Your Environment.
First, you must decide where the repository is to reside. For this example, it's $HOME/cvs.
To create an empty repository, enter the following command:
cvs -d$HOME/cvs init
If you look in $HOME/cvs, you'll see a directory called CVSROOT. It contains internal administrative files for CVS.
The -d option to cvs tells CVS where to find the repository. The init command tells CVS to create a new repository. The -d option is considered a global option, because it appears before the init command. The general format of a CVS command is:
cvs [global options] command [command-specific options] file names
Once you've created the repository, you need to edit these files in the CVSROOT directory:
A user can't be in both files.
There are two ways of getting source into the repository: adding new files or importing an existing directory tree. Let's look at creating new files first.
Since we're going to be working with a new repository, you have to first create the local working copy. But there's nothing there, is there?
You can check out the CVSROOT directory mentioned in the previous section, as you can any other directory. Since that's all you have, you'll have to start with that. You also need to make a place for the local copy, which is called your sandbox (because we all like playing in sandboxes, right?) and put it in your home directory.:
cd $HOME mkdir sandbox cd sandbox
Now we need to get our working copy of the repository:
cvs -d$HOME/cvs checkout .
or:
cvs -d$HOME/cvs get .
The dot (.) for the filename translates to "give me the entire repository."
You'll notice a directory called CVS in every directory that you've checked out. CVS uses this directory to store information about where in the repository the files belong, the versions of the files, and so on. Don't change any of the information in this directory.
 |
If you create a new project by copying directories from one part of your sandbox to another, don't copy the CVS directory. If you do, your project probably won't get stored where you expect in the repository. |
Now that we have a working copy, we can create some directories and files to demonstrate how to check in and out. We'll start with the standard "Hello, world" C program. It's good practice to keep all of your projects in separate directory structures, so we'll also create a new directory for our project.
To make the project directory:
mkdir myproj
Now we have to add this directory to the CVS repository:
cvs -d$HOME/cvs add myproj
It's time to create our test file. Make sure you're in the project directory:
cd myproj
Now use your favorite editor to create a file called foo.c with the following contents:
#include <stdio.h>
int main (int argc, char *argv[]) {
printf ("Hello, world.\n");
}
Adding the file is very similar to adding the directory:
cvs add foo.c
Notice that we left out the -d option to cvs. This is intentional. When you check out a directory, CVS creates a directory of its own for status and administrative files, so that it knows which repository this directory was checked out from. All future operations apply to this repository.
This command tells CVS that you want to add the file. It isn't really added yet; CVS needs you to explicitly tell it when you've finished making changes to your local copy of the repository. This lets you change or add several files or directories in your own time, and then tell CVS to take the changes all at once when they're ready. You use the commit command to do this.
The commit or ci ("check in") command tells CVS to make the repository look like your local copy. If multiple people are using the same repository, it's a little different, but for now, we assume that you're the only person using the repository:
cvs commit foo.c
or:
cvs ci foo.c
When you do this, CVS starts an editor to let you enter a description of the file. Type in something meaningful, such as "A file to test the basic functionality of CVS." This is completely free-form, so you can add whatever message you like. When you're finished, save and exit. CVS then tells you the file is committed.
It's probably easy to see that adding an existing source tree to CVS using the sequence of add and commit commands outlined above is tedious for more than a couple of files. In these cases, we'll use the import command. We'll cover the most basic use of this command in this section. Later on, we'll look at some more advanced things that you can do with it.
The import command assumes you have a directory tree somewhere on your disk. It must not be in either your repository or your local copy of the repository. To add the entire tree to your CVS repository, use the following format:
cd source_to_add cvs -drepository_path import path_in_repository vendor init
and provide a comment when the editor appears.
This may seem a little odd at first, but the import command has other uses than simply importing. It always imports the contents of the current working directory. The path_in_repository tells CVS to create this path within the repository and to put the contents of the current directory there.
CVS uses the last two arguments -- vendor and init -- to create a branch (see "Concurrent development: branching and merging" later in this chapter) and a tag for the imported files. They aren't applicable if you're importing your own software, but CVS requires them anyway.
You can see the status of the file by using the status or stat command:
cvs status foo.c
This gives output similar to the following:
=================================================================== File: foo.c Status: Up-to-date Working revision: 1.1 Tue Jun 3 17:14:55 2003 Repository revision: 1.1 /home/fred/cvs/myproj/foo.c,v Sticky Tag: (none) Sticky Date: (none) Sticky Options: (none)
When we created foo.c, we didn't put any comments in! We should probably fix that. Using your favorite editor, add the following line to the top of foo.c:
/* This is a file to test cvs */
Now look at the status:
=================================================================== File: foo.c Status: Locally Modified Working revision: 1.1 Tue Jun 3 17:14:55 2003 Repository revision: 1.1 /home/fred/cvs/myproj/foo.c,v Sticky Tag: (none) Sticky Date: (none) Sticky Options: (none)
The status has changed to Locally Modified. This is your signal that you've made changes, but have yet to tell CVS about them. Let's do that now:
cvs commit foo.c
As before, an editor appears asking for a log message. This is a little different from when adding a file. This time, it's the reason for that change or a quick synopsis of what the change is. Again, it's free-from so you can add what you like. We'll say Added comments for clarity. Save and exit.
The status is now:
=================================================================== File: foo.c Status: Up-to-date Working revision: 1.2 Tue Jun 3 17:30:49 2003 Repository revision: 1.2 /home/fred/cvs/myproj/foo.c,v Sticky Tag: (none) Sticky Date: (none) Sticky Options: (none)
The revision number is 1.2 instead of 1.1. We now have two separate revisions of foo.c, so now we can see what changed between them and why the changes were made. To find out why, we need to look at the log messages that were entered every time a commit was performed:
cvs log foo.c RCS file: /home/fred/cvs/myproj/foo.c,v Working file: foo.c head: 1.2 branch: locks: strict access list: keyword substitution: kv total revisions: 2; selected revisions: 2 description: ---------------------------- revision 1.2 date: 2003/06/03 17:35:43; author: fred; state: Exp; lines: +2 -0 Added comments for clarity. ---------------------------- revision 1.1 date: 2003/06/03 17:19:34; author: fred; state: Exp; A file to test the basic functionality of CVS ===================================================================
To see what changed between the two revisions, use the diff command:
cvs diff -r1.1 foo.c Index: foo.c =================================================================== RCS file: /home/fred/cvs/myproj/foo.c,v retrieving revision 1.1 retrieving revision 1.2 diff -r1.1 -r1.2 0a1,2 > /* This is a file to test cvs */ >
The last lines, starting with diff -r1.1 -r1.2z, show the actual differences using the standard diff format (see the Utilities Reference).
You may have noticed that in the diff command above, we specified only one revision, by using the -r option. CVS assumes the second revision is the same as that of foo.c in your sandbox. We saw from the last status command that the working revision was 1.2, so that's the second revision. We could have defined the revision explicitly instead by using a second -r option:
cvs diff -r1.1 -r1.2 foo.c Index: foo.c =================================================================== RCS file: /home/fred/cvs/myproj/foo.c,v retrieving revision 1.1 retrieving revision 1.2 diff -r1.1 -r1.2 0a1,2 > /* This is a file to test cvs */ >
The results are exactly the same.
CVS automatically traverses directory trees, starting with your current working directory (if you don't specify a filename or a directory name). For example:
cvs stat
gives the status of all files in the current working directory and in any other directories below it.
This feature is quite handy for making changes to various portions of a tree over time. To check in the whole set of changes at once, you just go to the root of the tree and use:
cvs commit
You're prompted for only one log message. The same message is applied to all of the commits made as a result of this single command.
Sometimes you need to work on more than one version of a file. For example, you might need to fix bugs in a released version of a program while you're working on new features for a future release. CVS makes this easier by letting you branch your files.
When you create a branch, CVS effectively creates another copy of a file or files and lets you edit either version. CVS keeps track of which changes apply to which version.
The main development stream in CVS is called the head. You could decide to develop new features on the head branch and create separate branches for released software.
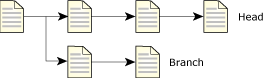
Branching a file in CVS.
For example, let's suppose you're releasing version 1.0 of your new product, Stella, and that this product includes a file called foo.c. You can create a branch for this release like this:
cvs tag -b "Stella_1.0" foo.c
The tag, Stella_1.0, is a sticky tag; any changes that you make in your sandbox are associated with the Stella_1.0 branch, not the head. If you want to work on the head, you can update your sandbox, specifying the -A option, which clears the sticky tags:
cvs update -A
or:
cvs up -A
What if you need to have both versions checked out? You could keep updating your sandbox to use the head (as shown above) and the branch (cvs update -r Stella_1.0), but keeping track of which version you're working on could be difficult. Instead, you can check out the branch in another directory:
cd ~/cvs mkdir version1.0 cd version1.0 cvs checkout -r Stella_1.0 path_to_the_files
So, you've made a change in one branch, and you need to make it in the other. You could edit the files twice, but that isn't very efficient. Instead, you could get CVS to merge one branch onto another.
 |
It's usually easier to merge a branch onto the head than vice versa. |
To merge the changes in foo.c in your Stella_1.0 branch into the version on the head, go to where you have the head-branch version checked out into your sandbox, then type:
cvs update -j Stella_1.0 foo.c
|
It's a good idea to check the file to make sure CVS merged the changes correctly; never trust a machine. |
Sometimes, the changes you made in one branch conflict with those you made in another. If this happens, CVS displays a C before the filename when you merge the versions. CVS leaves both versions of the conflicting lines in place, but marks them with rows of greater-than, equals, and less-than signs. You should edit the file to correct the discrepancies, and then check the corrected version into CVS.
When you remove a file from the repository, CVS puts it into the attic. Each directory in the repository has a subdirectory called Attic. You can't check the Attic out into your sandbox, but you can examine its contents through a web interface to CVS.
To delete a file (say, phoenix.c):
rm phoenix.c
cvs remove phoenix.c
or:
cvs rm phoenix.c
If you later need to restore the file:
cvs log phoenix.c | less
cvs checkout -r 1.3 my_project/phoenix.c
or:
cvs get -r 1.3 my_project/phoenix.c
The -r option sets a sticky tag.
mv phoenix.c save_phoenix.c cvs update -A
mv save_phoenix.c phoenix.c cvs add phoenix.c
Setting up a CVS server is similar to setting up a local repository (see "Creating a repository"), but you also have to the following:
pserver 2401/tcp
pserver stream tcp nowait root /usr/bin/cvs cvs -b /usr/local/bin -f --allow-root=root_dir pserver
where root_dir is the path that you want to use for your CVS root directory. By convention, the path should end with CVSRoot, but it isn't enforced.
You can have more than one root directory; just add multiple instances of --allow-root=root_dir.
cvs -d root_dir init
This creates the root_dir directory and populates it with all the things it needs in there.
For more information, see http://www.nongnu.org/cvs/.
|
|
|
|